NAMD, 60,000 atoms benchmarks
The system used for the test comprised 60660 atoms, with an orthogonal PBC box of dimensions ~124x77x63, an inner step of 2 fs, nonbonded every 4 fs, and electrostatics every 8 fs (script include below). All runs were allowed to run till stabilisation. The table below reports days per nanosecond of simulation for each combination indicated.
NAMD script used for these tests
| 4 cores | 8 cores | 12 cores | 16 cores | |
|---|---|---|---|---|
| NAMD 2.6 TCP | 2.04 | 1.28 | 1.95 | 1.57 |
| NAMD 2.6 UDP | 2.07 | 1.33 | 1.12 | 0.99 |
| NAMD 2.5 UDP | 2.16 | 1.36 | 1.10 | 0.98 |
For the runs shown above, the PME grid was 128x80x64, all cores were used for FFT and the nodelist file was a simple core list using the eth0 interface:
group main host 10.0.0.11 host 10.0.0.11 host 10.0.0.11 host 10.0.0.11 host 10.0.0.12 ...
Keeping constant the number of cores (16) and the NAMD version (2.6 UDP), we have:
| Modification of above scenario | Days per nsec | nsec per day |
|---|---|---|
| Use eth1 (10.0.1.x) in nodelist but 10.0.0.1 for charmrun | 0.95 | 1.05 |
| Use eth1 (10.0.1.x) in nodelist and 10.0.1.1 for charmrun | 0.96 | 1.04 |
| Use a mix of eth0 and eth1 in nodelist, 10.0.0.1 for charmrun | 0.97 | 1.03 |
| Use the +atm namd command-line flag | 0.82 | 1.22 |
| Use the +atm +giga NAMD command-line flags | 0.77 | 1.30 |
| Use the +giga namd command-line flag | 0.76 | 1.31 |
| Use +giga, mixed eth0 & eth1, 10.0.0.1 for charmrun | 0.74 | 1.35 |
The current best looks like this (with a doubt concerning the choice for useip):
charmrun /usr/local/namd/namd2 +p16 +giga ++useip 10.0.0.1 equi.namd
Keeping the above line constant, try with different nodelist files and VLAN settings on the switch:
| VLANs in use ? | Nodelist form | Days per nanosecond |
|---|---|---|
| No | 10.0.0.11, 10.0.0.11, 10.0.0.11, 10.0.0.11, 10.0.0.12, … | 0.77 |
| No | 10.0.1.11, 10.0.1.11, 10.0.1.11, 10.0.1.11, 10.0.1.12, … | 0.77 |
| No | 10.0.0.11, 10.0.1.11, 10.0.0.11, 10.0.1.11, 10.0.0.12, … | 0.74 |
| No | 10.0.1.11, 10.0.0.11, 10.0.1.11, 10.0.0.11, 10.0.1.12, … | 0.74 |
It appears that the absence of VLANs doesn't affect performance significantly, so go back to two established VLANs (to keep traffic segragated).
Since we are here, do a quick test with all 32 cores to cheer-up:
# charmrun /usr/local/namd/namd2 +p32 +giga ++useip 10.0.0.1 equi.namd > LOG & # days_per_nanosecond LOG 0.56717 0.522217 0.510001 ...
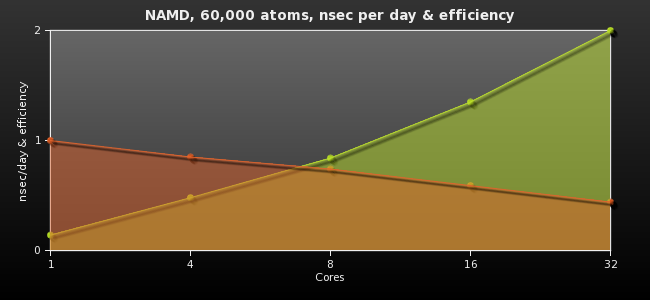
Try some additional NAMD parameters: +idlepoll (no effect), +eth (no effect), +stacksize (no effect), +LBObjOnly (failed), +truecrash (no effect), +strategy USE_MESH/USE_GRID. To recap up to now, the following table compares number of cores vs. timings & efficiency. Efficiency is defined as [100*(days/nsec) for one core] / [ n*(days/nsec) for n cores]
| Days per nsec | nsec per day | Efficiency (%) | |
|---|---|---|---|
| 1 core | 7.05 | 0.14 | 100% |
| 4 cores | 2.07 | 0.48 | 85% |
| 8 cores | 1.19 | 0.84 | 74% |
| 16 cores | 0.74 | 1.35 | 59% |
| 32 cores | 0.50 | 2.00 | 44% |
Test two different NAMD executables as provided by the developers using 16 cores (measurements in days per nanosecond):
| 16 cores | 32 cores | |
|---|---|---|
| Linux-i686 | 0.74 | 0.51 |
| Linux-amd64 | 0.56 | 0.43 |
Using 16 cores with a one-by-one nodelist file as described here : 0.53 days per nsec.
Start messing with the namd run per se. Check PMEprocessors: run NAMD using the command line:
/usr/local/namd/charmrun /usr/local/namd/namd2 +p32 +giga ++useip 10.0.0.1 equi.namd
and vary the PMEprocessors and whether they are on the same node(s) or different (measurements in days per nsec):
| PMEprocessors 32 (all cores) | 0.44 |
|---|---|
| PMEprocessors 16 (two per node) | 0.43 |
| PMEprocessors 4 (on four different nodes) | 0.45 |
Try increasing 'stepsPerCycle' and 'pairlistdist' to improve parallel scaling. Try using '+asyncio +strategy USE_HYPERCUBE'. With all that, the improvement is rather small, ending to about 0.40 days per nanosecond.
 cpu: 4%")